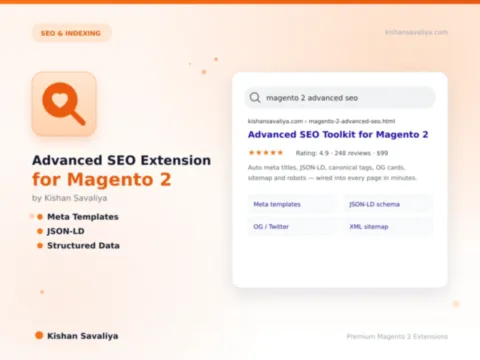
Built for Magento 2
Complete robots and crawler-policy control for Magento 2.
Complete robots and crawler-policy control for Magento 2. One module takes over /robots.txt at the router layer, emits an X-Robots-Tag HTTP response header on every frontend HTML page, adds per-user-agent allow/disallow rows via an admin…
Key Features:
Additional Services
Built-in from day one. No add-ons, no upsell, no licence keys to renew.
Complete robots and crawler-policy control for Magento 2.
Adobe Magento Extension Quality Program, passes with zero severity-10 violations.
Vanilla JS, no jQuery dependency. Drop-in compatible with both default Luma and Hyva themes.
Lifetime updates with every Magento release. No subscription, no licence keys, no upsells.
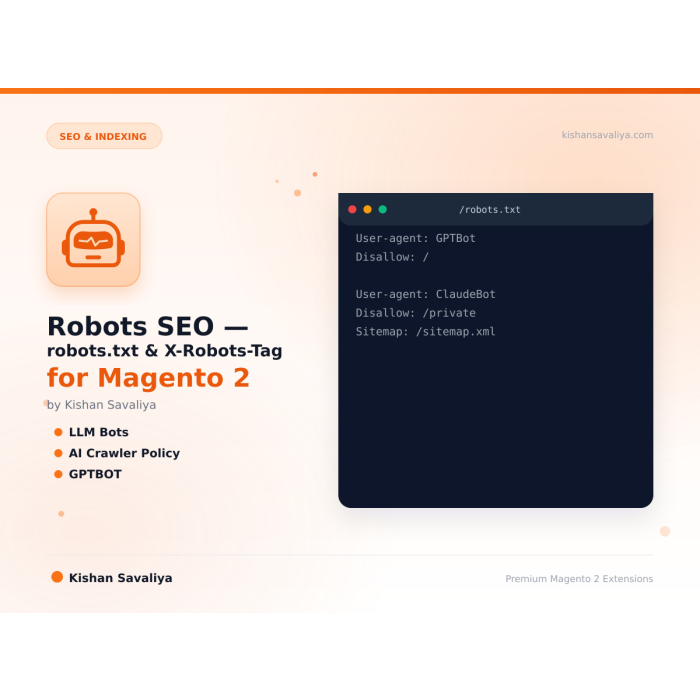
Panth Robots SEO is a robots.txt and X-Robots-Tag controller for Magento 2 and Adobe Commerce with dedicated LLM crawler policy for 14 AI bots.
The module takes over /robots.txt at the router layer (so it ignores the static pub/robots.txt file that Magento ships) and emits an X-Robots-Tag HTTP response header on every frontend HTML page. An admin grid lets you add per-user-agent allow / disallow rows without editing files, and a preview pane renders the exact body that will be served before you save the policy.
A dedicated LLM Bot Policy section toggles 14 modern AI crawlers individually, GPTBot, ChatGPT-User, ClaudeBot, PerplexityBot, Google-Extended, Bytespider, CCBot, anthropic-ai, Applebot-Extended, plus YouBot, PetalBot, Diffbot, AI2Bot, Omgilibot, and Timpibot. Each toggle writes the matching User-agent block, so blocking ChatGPT scraping or allowing Perplexity citation is a one-click admin change instead of a deploy.
Mass actions cover bulk enable / disable, the module is theme-agnostic (works identically on Hyvä and Luma), and the dedicated frontName panth_indexnow-style route registration keeps controller resolution clean even when other SEO modules are installed alongside it.
Full Magento 2 robots policy control across robots.txt, X-Robots-Tag headers, and per-bot LLM toggles.
/robots.txt takeover with admin grid CRUD per user-agentComplete robots and crawler-policy control for Magento 2. One module takes over
/robots.txtat the router layer, emits anX-Robots-TagHTTP response header on every frontend HTML page, adds per-user-agent allow/disallow rows via an admin grid, and toggles fourteen modern LLM / AI crawlers (GPTBot, ClaudeBot, PerplexityBot, Google-Extended, Bytespider, CCBot, Applebot-Extended, Meta-ExternalAgent, Amazonbot, Cohere-AI, and more) with a single click. Every directive passes a CRLF-safe validator before it ever reaches the wire. Works identically on Hyva and Luma.
Magento's native robots handling is three things that no longer add up: a static robots.txt file on disk, a single admin textarea buried under Content → Design → Configuration that overwrites it, and no X-Robots-Tag header control whatsoever. There is also no UI for the new generation of AI crawlers, GPTBot, ClaudeBot, PerplexityBot, Google-Extended, Bytespider, so stores either open their data to every model trainer by default or hand-edit the file on every deploy. Panth Robots SEO unifies all three layers (robots.txt body, robots meta, X-Robots-Tag header) into one coherent admin surface with a dedicated controller, a declarative schema-backed policy grid, and a directive validator that makes CRLF header injection structurally impossible.
End-to-end admin flow, enable the module, toggle a few LLM bots, add a policy row, preview the generated robots.txt, curl /robots.txt on both Hyva and Luma, and confirm the X-Robots-Tag header on a customer-account page. Click to play.
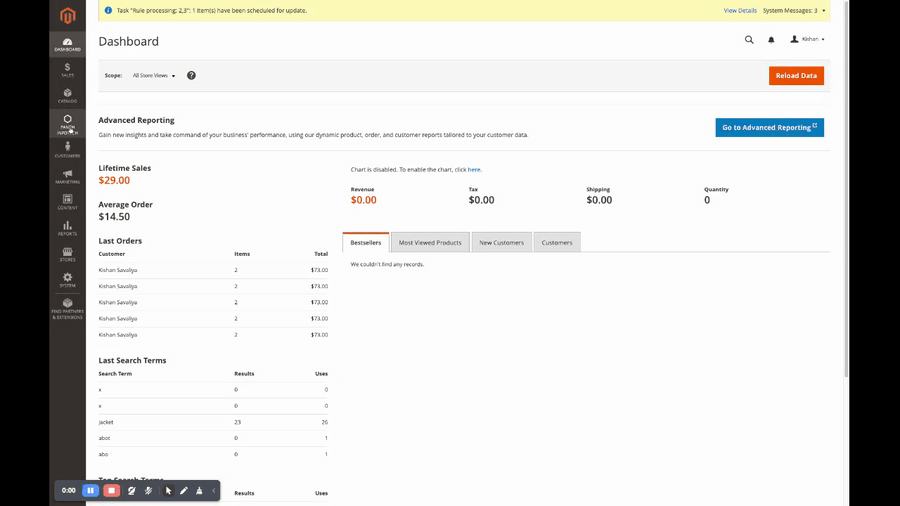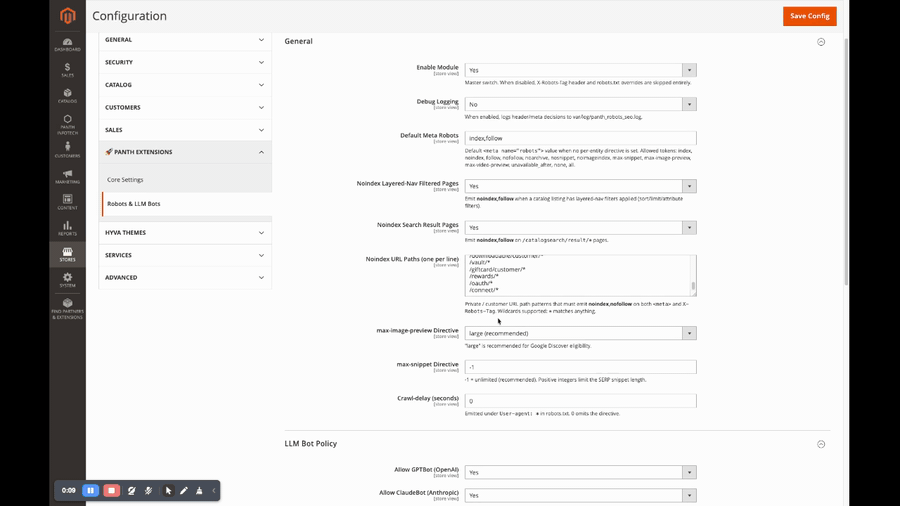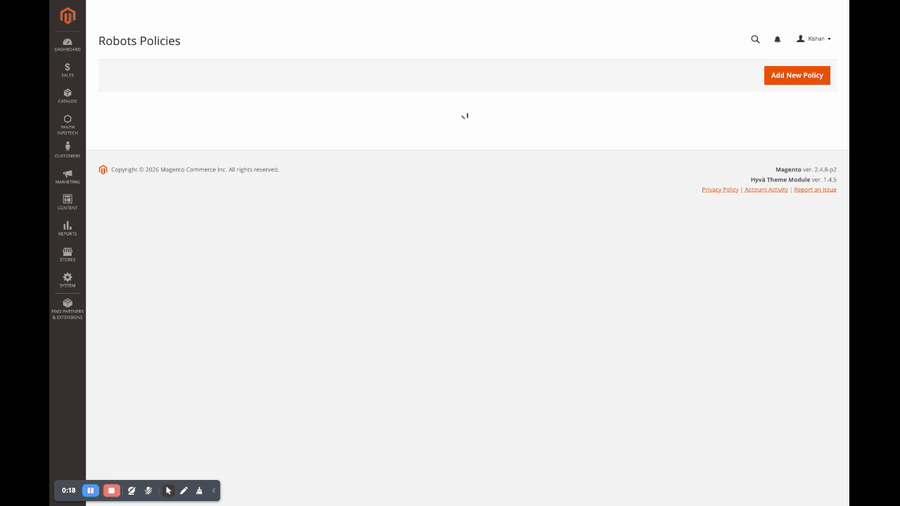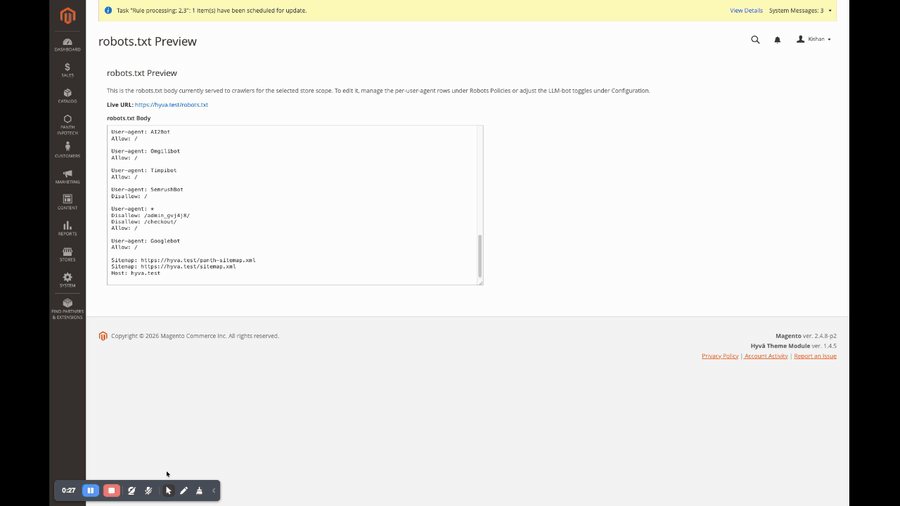
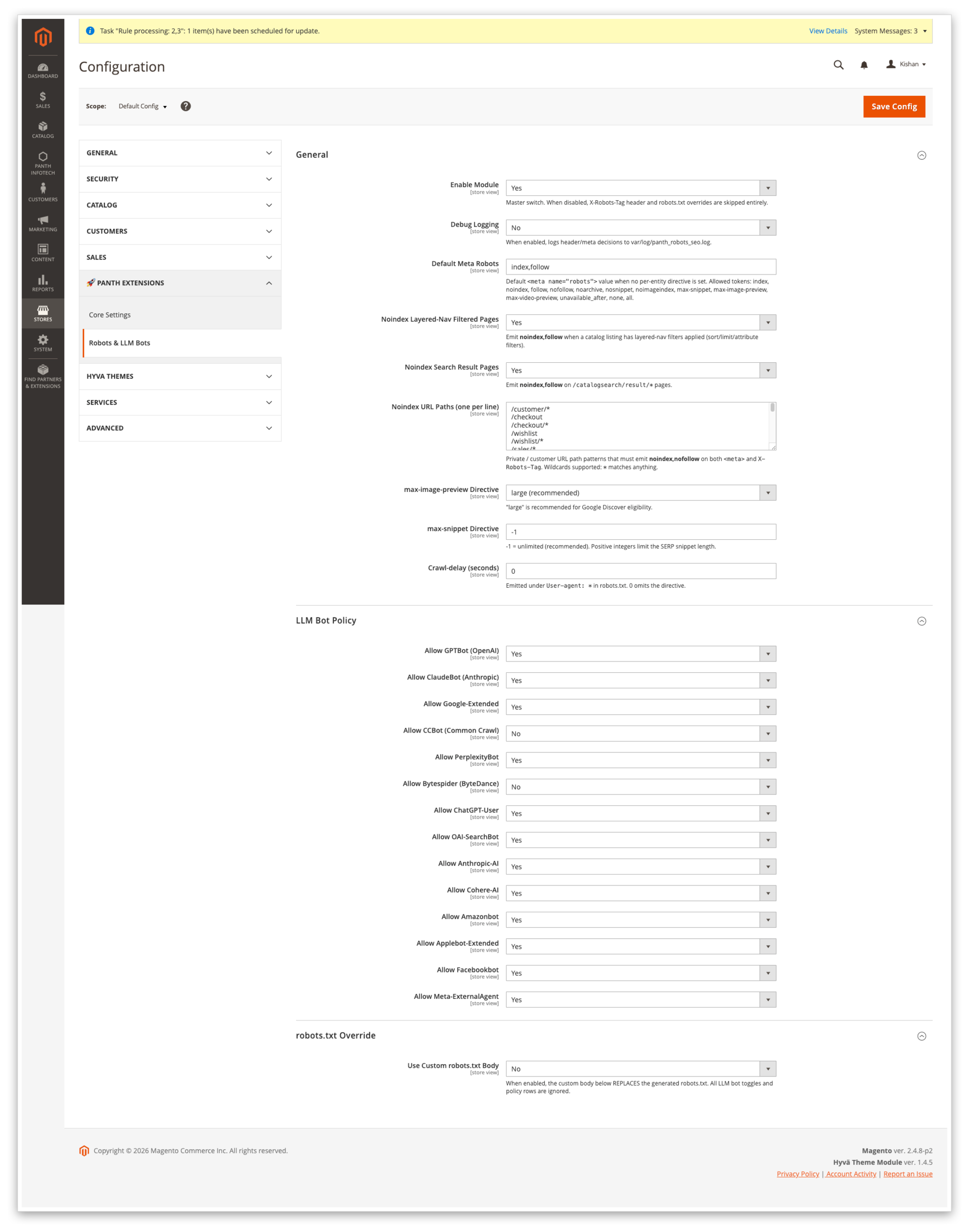
Global configuration, toggle the module, pick the default <meta name="robots"> value, configure layered-nav and catalogsearch noindex, edit the noindex path list, set max-image-preview / max-snippet / Crawl-delay.
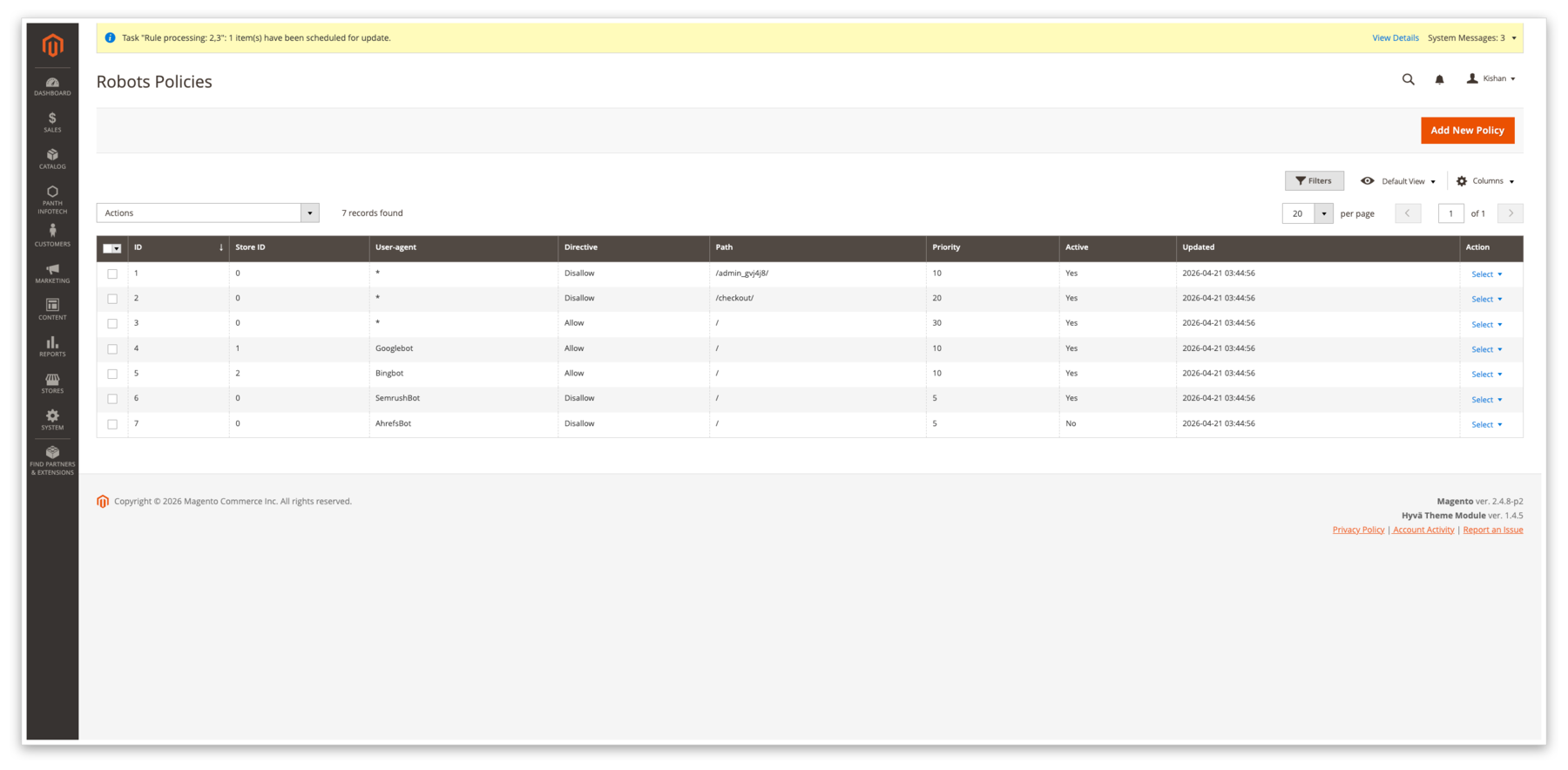
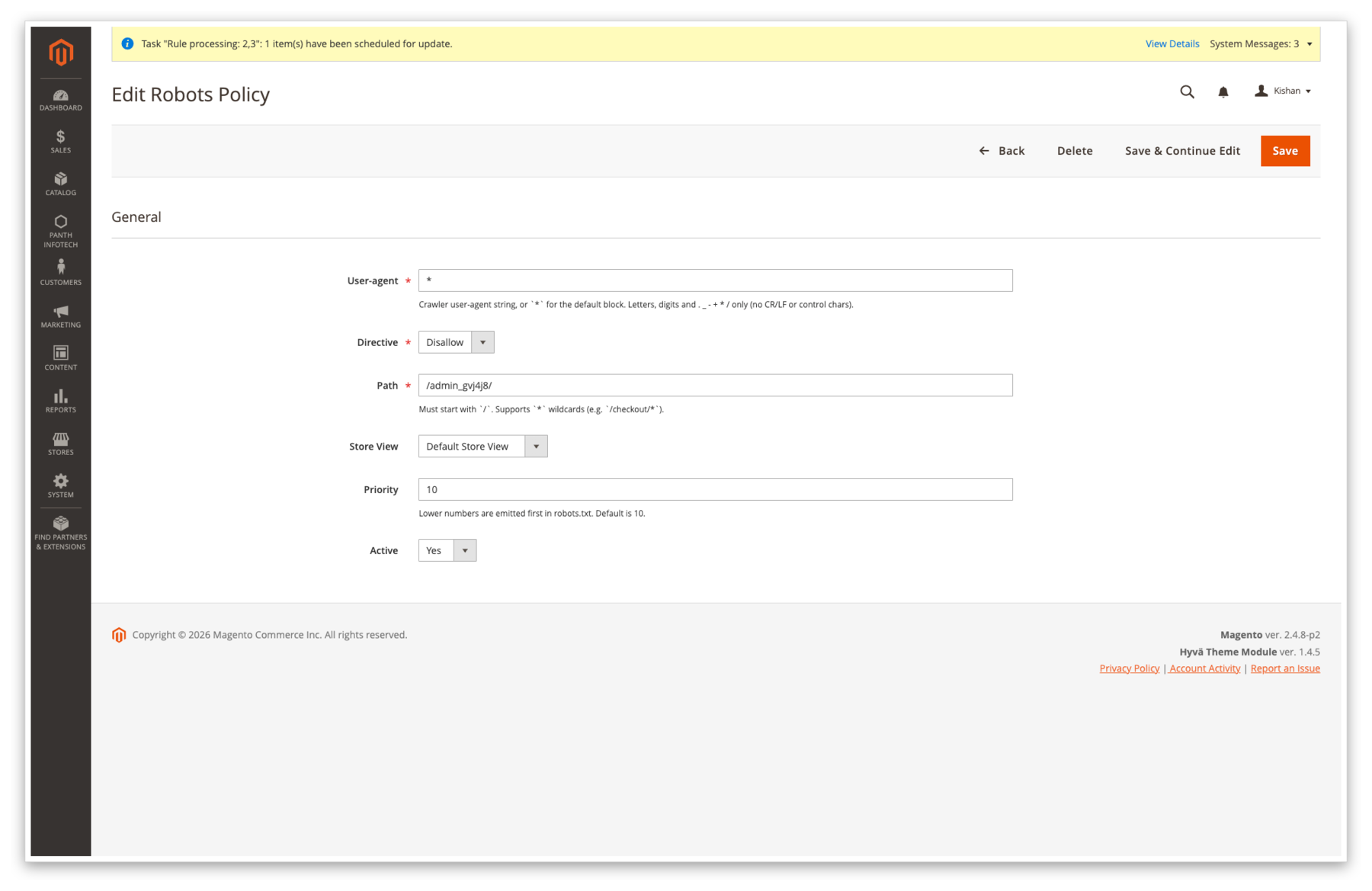
Robots Policies grid, one row per (user-agent, path, directive, store_id) tuple. Filter by store, mass-enable / disable / delete, inline priority column so the evaluator knows which rule wins when two patterns overlap.
Edit form, policy row, pick a user-agent (* for the default block, or GPTBot, ClaudeBot, a custom UA, etc.), pick allow / disallow, enter a path, scope to a store view, set priority and active flag. The UA and path fields are validated against a whitelist regex before save.
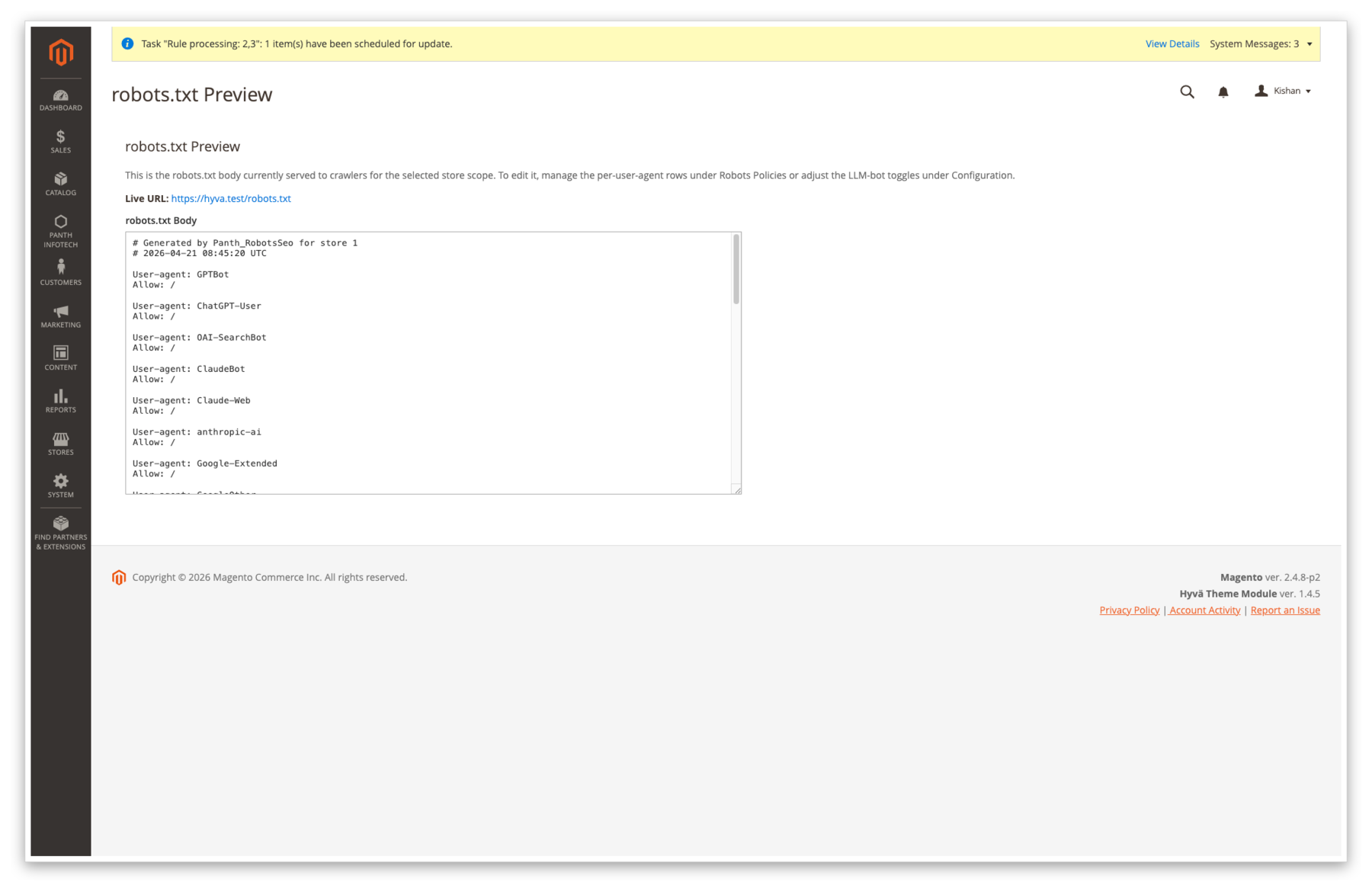
robots.txt preview, dedicated Panth Infotech → Robots & LLM Bots → robots.txt Preview page renders the live body exactly as the frontend will serve it, with a store-switcher so you can verify each store view before rolling to production.
| Feature | Description |
|---|---|
Dynamic /robots.txt per store view |
Built on the fly from LLM-bot toggles (emitted as User-agent: <bot>\nDisallow: / blocks when disabled), a User-agent: * block with admin policy rows and Crawl-delay, then Sitemap: and Host: lines. No static file ever leaves disk. |
| 14 LLM / AI crawler toggles | One-click allow/disallow for GPTBot (GPTBot), ChatGPT-User (ChatGPT-User), OAI-SearchBot (OAI-SearchBot), ClaudeBot (maps both ClaudeBot and Claude-Web), Anthropic-AI (anthropic-ai), Google-Extended (maps both Google-Extended and GoogleOther), PerplexityBot (PerplexityBot), Cohere-AI (cohere-ai), CCBot (CCBot), Bytespider (Bytespider), Amazonbot (Amazonbot), Applebot-Extended (Applebot-Extended), FacebookBot (FacebookBot), Meta-ExternalAgent (meta-externalagent). |
X-Robots-Tag response header |
Added to every frontend HTML response by Plugin\Response\XRobotsTagPlugin with max-image-preview:<large|standard|none> and max-snippet:<int> appended to the chosen directive. Handled before Response::sendResponse() so the header is always present. |
| Noindex path matcher | Service\NoindexPathMatcher walks an admin-editable list of path patterns (* wildcards supported). Defaults cover /customer/*, /checkout*, /wishlist*, /sales/*, /contact*, /catalogsearch/*, /multishipping/*, /newsletter/manage*, /review/customer/*, /captcha*, /sendfriend/*, /paypal/*, /downloadable/customer/*, /vault/*, /giftcard/customer/*, /rewards/*, /oauth/*, /connect/*. |
| Layered-nav / sort-filter noindex | When a catalog listing has any ?p=, ?dir=, ?order=, ?limit=, or layered-nav attribute query parameter, the header flips to noindex, follow so filtered permutations don't dilute the canonical listing. |
| Catalogsearch noindex | /catalogsearch/result/* pages emit noindex, follow by default, searches are inherently ephemeral and shouldn't be indexed. |
| HTTP-status-aware override | 404, 410, 500 and 503 responses hard-override the header to noindex, nofollow regardless of config, so error pages can never leak into the index. |
| Non-HTML asset noindex | Requests ending in .pdf, .doc, .docx, .xls, .xlsx emit noindex, nofollow, stops support docs and spec sheets from displacing the canonical product page in the SERP. |
robots.txt custom-body override |
robots_txt/override_enabled = 1 pastes robots_txt/custom_body verbatim into the response and skips the entire generation pipeline. CRLF is normalised to LF on write. |
| Admin CRUD grid | panth_seo_robots_policy table with a full UI-component grid, per-UA, per-path, per-store-view allow/disallow rows with priority and active flag. Dedicated robots.txt Preview admin page renders the live output. |
| CRLF-injection-safe | Every directive string passes Service\DirectiveValidator (printable-ASCII whitelist, rejects \r, \n, \0). Every path and UA is validated against a whitelist regex before the DB write. |
Seven cooperating pieces:
Controller\Robots\Index at route seo_robots/robots/index serves GET /robots.txt with the generated or override body, Content-Type: text/plain; charset=utf-8.Setup\Patch\Data\InstallRobotsTxtRewrite writes the url_rewrite row that maps /robots.txt to the module controller at install time; RefreshRobotsTxtRewrite re-points an existing stale target_path row left behind by Panth_AdvancedSEO so upgrades are a no-op.etc/frontend/di.xml disables the core Magento\Framework\App\RouterList entry for robots, Magento's built-in robots router no longer intercepts /robots.txt before the url_rewrite layer, so our controller wins.Plugin\Response\XRobotsTagPlugin is a beforeSendResponse plugin on Magento\Framework\App\Response\Http. It inspects the request path, status code, and rendered Content-Type, then sets X-Robots-Tag once per response.Model\Robots\PolicyResolver aggregates panth_robots_seo/llm_bots/* toggles + rows from panth_seo_robots_policy + the configured Crawl-delay + Sitemap: references into the final robots.txt body for a given store.Model\Robots\MetaResolver computes the per-entity robots meta string, used by the plugin and (when Panth_AdvancedSEO is present) by the shared panth_seo_resolved.robots cache column.Service\NoindexPathMatcher + Service\DirectiveValidator, the first decides whether a given request path is "private"; the second is the single chokepoint every directive string passes through before it hits a response header or the robots.txt body.Open Admin → Panth Infotech → Robots & LLM Bots → Robots Policies to reach the grid (route panth_robots_seo/policy/index).
| Field | Description |
|---|---|
| User-agent | The UA string to match, * for the default block, GPTBot, ClaudeBot, Applebot-Extended, a custom crawler, etc. Validated against /^[A-Za-z0-9._\-+*\/ ]+$/ on save. |
| Directive | allow or disallow. Single source of truth consumed by PolicyResolver. |
| Path | The path fragment the directive applies to. Must start with /, no control bytes. * wildcards allowed. |
| Store View | 0 applies to all stores; a non-zero value scopes the row to one store view. Foreign-keyed to store.store_id with ON DELETE CASCADE. |
| Priority | Lower numbers are emitted first within the same user-agent block. |
| Active | Per-row enable/disable. Inactive rows are never rendered. |
Select rows and choose Enable, Disable or Delete from the grid mass-action menu.
The Panth Infotech → Robots & LLM Bots → robots.txt Preview sub-menu (route panth_robots_seo/robots/index) renders the live body for the currently selected store, exactly as the frontend controller would serve it, helpful for dry-running changes before they go public.
GET /robots.txttext/plain; charset=utf-8Panth\RobotsSeo\Controller\Robots\Index at route seo_robots/robots/index./robots.txt is served by our controller via a url_rewrite row installed by Setup\Patch\Data\InstallRobotsTxtRewrite. The core Magento_Robots router is disabled via etc/frontend/di.xml so it never intercepts the request ahead of the url_rewrite layer.
If you are upgrading from Panth_AdvancedSEO where /robots.txt was already mapped to that module's controller, the RefreshRobotsTxtRewrite patch runs on the next setup:upgrade and rewrites the stale target_path to point at the new controller, zero manual DB surgery required.
User-agent: CCBot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: *
Crawl-delay: 0
Disallow: /customer/
Disallow: /checkout/
Allow: /
Sitemap: https://your-store.test/sitemap.xml
Host: your-store.test
Plugin\Response\XRobotsTagPlugin runs beforeSendResponse on Magento\Framework\App\Response\Http and applies the following order of precedence:
/robots.txt, never sets a header on the robots.txt response itself.noindex, nofollow, no further checks..pdf, .doc, .docx, .xls, .xlsx → hard noindex, nofollow./catalogsearch/result/* when noindex_search_results = Yes → noindex, follow.noindex_paths match, Service\NoindexPathMatcher → noindex, nofollow (and the matching meta).noindex, follow.panth_robots_seo/general/default_directive (e.g. index, follow).In every case the final string is appended with , max-image-preview:<value> and , max-snippet:<int> from general config, then passed through Service\DirectiveValidator before being set on the response.
Panth\RobotsSeo\Controller\Adminhtml\AbstractAction, declares its own ADMIN_RESOURCE constant (Panth_RobotsSeo::policies, Panth_RobotsSeo::preview), and enforces ACL via _isAllowed(). No route is reachable without a valid admin session.HttpPostActionInterface on mutating paths. Save, Delete, MassDelete, MassStatus all implement HttpPostActionInterface so GET is rejected at the framework level. Form-key validation runs on every POST.DirectiveValidator whitelist + control-byte rejection. Every directive string written to X-Robots-Tag or the robots.txt body passes through Service\DirectiveValidator::assertSafe(), rejects any string containing \r, \n, \0, or bytes outside printable-ASCII. CRLF header injection is structurally impossible.robots_txt/custom_body has \r\n → \n normalisation applied on render so a pasted Windows-style newline can't smuggle a second response header.enabled, noindex_paths, every llm_bots/* toggle, and the custom body resolve at ScopeInterface::SCOPE_STORES, a store-specific value never leaks into another store./^[A-Za-z0-9._\-+*\/ ]+$/ and paths that do not start with / or contain control bytes, before the row is written.escapeHtml() and wraps it in <pre> tags, so a hostile custom body can never execute script on an admin browser./robots.txt returns a 404 or a Luma 404 HTML pageYou are likely sitting on a stale url_rewrite row left behind by Panth_AdvancedSEO whose target_path still points at the old controller. Run bin/magento setup:upgrade, the RefreshRobotsTxtRewrite patch fires idempotently and rewrites the row to the new target. Follow with bin/magento cache:clean config full_page.
X-Robots-Tag not appearing on /customer/* pagesUpgrade to ≥ 1.0.2. Earlier releases had a constructor-argument ordering bug that made the plugin skip the response when Panth_AdvancedSEO wasn't installed; 1.0.2 makes the dependency DI-nullable and the plugin always runs.
robots.txtpanth_robots_seo/llm_bots/<bot> resolves at store-view scope, not website or default.bin/magento cache:clean config full_page. The /robots.txt body is built live per request but the config it reads from is cached.robots_txt/override_enabled is No, when the override is on, every LLM toggle is ignored.override_enabled but nothing changesbin/magento cache:clean config full_page, the override flag and custom body are both pulled from cached config.custom_body was saved at the store scope you are viewing, not the default scope. Check with SELECT scope, scope_id, value FROM core_config_data WHERE path = 'panth_robots_seo/robots_txt/custom_body';.The module sets the X-Robots-Tag HTTP response header, not the <meta name="robots"> element. A layout hook that injects the <meta> tag into the page <head> is only wired when Panth_AdvancedSEO is also installed (it owns the page/main block override). If you need both, install mage2kishan/module-advanced-seo alongside this module; they share the panth_seo_robots_policy table and do not collide.
| Requirement | Supported |
|---|---|
| Magento Open Source | 2.4.4, 2.4.5, 2.4.6, 2.4.7, 2.4.8 |
| Adobe Commerce | 2.4.4-2.4.8 |
| PHP | 8.1, 8.2, 8.3, 8.4 |
| Hyva Theme | 1.0+ (fully compatible) |
| Luma Theme | Native support |
| Panth Core | ^1.0 (installed automatically) |
composer require mage2kishan/module-robots-seo
bin/magento module:enable Panth_Core Panth_RobotsSeo
bin/magento setup:upgrade
bin/magento setup:di:compile
bin/magento cache:flush
bin/magento module:status Panth_RobotsSeo
# Module is enabled
curl -s -o /dev/null -w '%{http_code}\n' https://your-store.test/robots.txt
# 200
curl -sI https://your-store.test/customer/account/login | grep -i x-robots-tag
# X-Robots-Tag: noindex, nofollow, max-image-preview:large, max-snippet:-1
Visit Admin → Panth Infotech → Robots & LLM Bots → Robots Policies to see the seeded policy grid.
Navigate to Stores → Configuration → Panth Infotech → Robots & LLM Bots.
| Setting | Path | Default | What it controls |
|---|---|---|---|
| Enable Module | panth_robots_seo/general/enabled |
Yes | Master switch. When No, the X-Robots-Tag plugin is a no-op and /robots.txt serves a stock User-agent: *\nAllow: /. |
| Debug Logging | panth_robots_seo/general/debug |
No | When Yes, every header and meta decision is written to var/log/panth_robots_seo.log. |
| Default Meta Robots | panth_robots_seo/general/default_directive |
index,follow |
Baseline directive applied when no per-entity / per-path override fires. Allowed tokens: index, noindex, follow, nofollow, noarchive, nosnippet, noimageindex, max-snippet, max-image-preview, max-video-preview, unavailable_after, none, all. |
| Noindex Layered-Nav Filtered Pages | panth_robots_seo/general/noindex_filtered |
Yes | Emit noindex, follow when a catalog listing has layered-nav or sort/limit/page query parameters. |
| Noindex Search Result Pages | panth_robots_seo/general/noindex_search_results |
Yes | Emit noindex, follow on /catalogsearch/result/*. |
| Noindex URL Paths | panth_robots_seo/general/noindex_paths |
(18-line seeded list, see above) | One-path-per-line list of private patterns; * matches anything. Matched by Service\NoindexPathMatcher. |
| max-image-preview Directive | panth_robots_seo/general/max_image_preview |
large |
Appended to every X-Robots-Tag. large is recommended for Google Discover eligibility. |
| max-snippet Directive | panth_robots_seo/general/max_snippet |
-1 |
-1 = unlimited. A positive integer caps SERP snippet length. |
| Crawl-delay (seconds) | panth_robots_seo/general/crawl_delay |
0 |
Emitted under User-agent: * in robots.txt. 0 omits the directive. |
| Setting | Path | Default | What it controls |
|---|---|---|---|
| Allow GPTBot (OpenAI) | panth_robots_seo/llm_bots/gptbot |
Yes | No = emits User-agent: GPTBot\nDisallow: /. |
| Allow ClaudeBot (Anthropic) | panth_robots_seo/llm_bots/claudebot |
Yes | Covers both ClaudeBot and Claude-Web. |
| Allow Google-Extended | panth_robots_seo/llm_bots/google_extended |
Yes | Covers both Google-Extended and GoogleOther. |
| Allow CCBot (Common Crawl) | panth_robots_seo/llm_bots/ccbot |
No | CCBot feeds dataset-scale training pipelines; blocked by default. |
| Allow PerplexityBot | panth_robots_seo/llm_bots/perplexitybot |
Yes | |
| Allow Bytespider (ByteDance) | panth_robots_seo/llm_bots/bytespider |
No | Bytespider ignores partial disallows; blocked by default. |
| Allow ChatGPT-User | panth_robots_seo/llm_bots/chatgpt_user |
Yes | |
| Allow OAI-SearchBot | panth_robots_seo/llm_bots/oai_searchbot |
Yes | |
| Allow Anthropic-AI | panth_robots_seo/llm_bots/anthropic_ai |
Yes | |
| Allow Cohere-AI | panth_robots_seo/llm_bots/cohere_ai |
Yes | |
| Allow Amazonbot | panth_robots_seo/llm_bots/amazonbot |
Yes | |
| Allow Applebot-Extended | panth_robots_seo/llm_bots/applebot_extended |
Yes | |
| Allow Facebookbot | panth_robots_seo/llm_bots/facebookbot |
Yes | |
| Allow Meta-ExternalAgent | panth_robots_seo/llm_bots/meta_externalagent |
Yes |
| Setting | Path | Default | What it controls |
|---|---|---|---|
| Use Custom robots.txt Body | panth_robots_seo/robots_txt/override_enabled |
No | When Yes, the custom body below REPLACES the generated output, every LLM toggle and policy row is ignored. |
| Custom robots.txt Body | panth_robots_seo/robots_txt/custom_body |
(empty) | Pasted verbatim into the response. CRLF is normalised to LF to prevent HTTP header smuggling. Leave empty to use the generated output. |
Every setting resolves at store-view scope, so each store can have a different LLM policy, noindex path list, or override body.
| Module Category | SEO & Indexing |
|---|---|
| Best For | All Sizes |
Talk to Kishan directly: written quote, scope and timeline within 24 hours. No sales call.
Robots SEO, robots.txt & X-Robots-Tag for Magento 2